
Impossible no more
We fuse AI into the DNA of your organization, creating and scaling self-learning systems that reinvent the very core of how you think, operate and innovate.
By combining the strengths of Human and Artificial Intelligence, we enable your teams to continually advance performance to new, previously impossible horizons.
Learn more

Data & AI transformation
Create exponential value through new, AI-powered revenue streams and business models.






B2B Sales Optimization Engine
What if we could use AI to deliver 100X lifetime ROI?


Supply Chain
What if we could use AI to reduce working capital by 18%?


Pricing & Revenue Management Solutions
What if we could use AI to increase annual contract value by 10%?


Promotion Optimization Engine
What if we could use AI to enhance bottom-line value by 30%?



GAIN
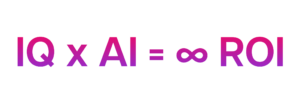


AI scalability requires AI capability.
Discover the programs we have built to fuse AI into your DNA at every level of your organisation.
We are Data & AI partner to the leaders of tomorrow.